Pipeline#
Datashader provides a flexible series of processing stages that map from raw data into viewable images. As shown in the Introduction, using datashader can be as simple as calling datashade(), but understanding each of these stages will help you get the most out of the library.
The stages in a datashader pipeline are similar to those in a 3D graphics shading pipeline:
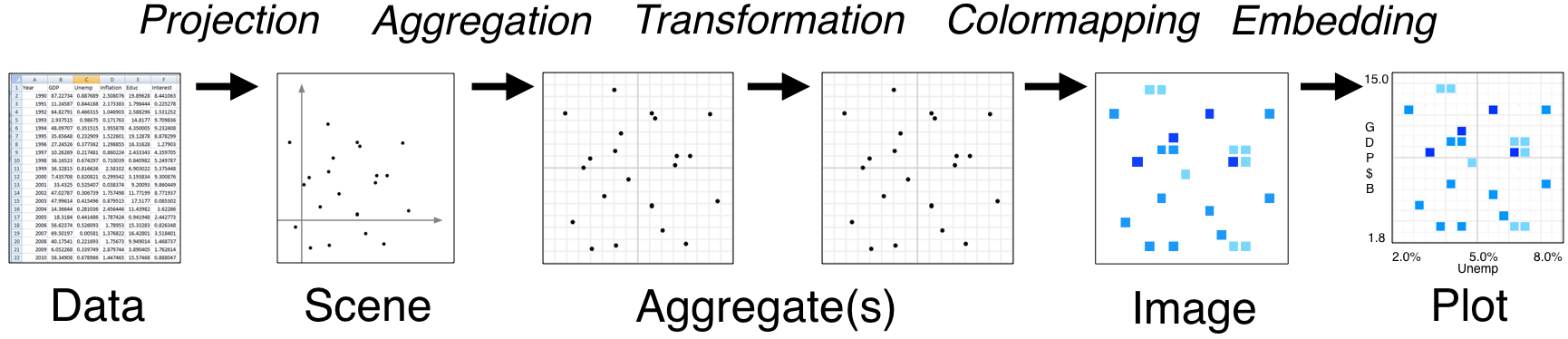
Here the computational steps are listed across the top of the diagram, while the data structures or objects are listed along the bottom. Breaking up the computations in this way is what makes Datashader able to handle arbitrarily large datasets, because only one stage (Aggregation) requires access to the entire dataset. The remaining stages use a fixed-sized data structure regardless of the input dataset, allowing you to use any visualization or embedding methods you prefer without running into performance limitations.
In this notebook, we’ll first put together a simple, artificial example to get some data, and then show how to configure and customize each of the data-processing stages involved:
Data#
For an example, we’ll construct a dataset made of five overlapping 2D Gaussian distributions with different σs (spatial scales). By default we’ll have 10,000 datapoints from each category, but you should see sub-second response times even for 1 million datapoints per category if you increase num.
import pandas as pd
import numpy as np
num=10000
np.random.seed(1)
dists = {cat: pd.DataFrame(dict([('x',np.random.normal(x,s,num)),
('y',np.random.normal(y,s,num)),
('val',val),
('cat',cat)]))
for x, y, s, val, cat in
[( 2, 2, 0.03, 10, "d1"),
( 2, -2, 0.10, 20, "d2"),
( -2, -2, 0.50, 30, "d3"),
( -2, 2, 1.00, 40, "d4"),
( 0, 0, 3.00, 50, "d5")] }
df = pd.concat(dists,ignore_index=True)
df["cat"]=df["cat"].astype("category")
Datashader can work many different data objects provided by different data libraries depending on the type of data involved, such as columnar data in Pandas or Dask dataframes, gridded multidimensional array data using xarray, columnar data on GPUs using cuDF, multidimensional arrays on GPUs using CuPy, and ragged arrays using SpatialPandas (see the Performance User Guide for a guide to selecting an appropriate library). Here, we’re using a Pandas dataframe, with 50,000 rows by default:
df.tail()
| x | y | val | cat | |
|---|---|---|---|---|
| 49995 | -1.397579 | 0.610189 | 50 | d5 |
| 49996 | -2.649610 | 3.080821 | 50 | d5 |
| 49997 | 1.933360 | 0.243676 | 50 | d5 |
| 49998 | 4.306374 | 1.032139 | 50 | d5 |
| 49999 | -0.493567 | -2.242669 | 50 | d5 |
To illustrate this dataset, we’ll make a quick-and-dirty Datashader plot that dumps these x,y coordinates into an image:
import datashader as ds
import datashader.transfer_functions as tf
%time tf.shade(ds.Canvas().points(df,'x','y'))
CPU times: user 1.01 s, sys: 138 ms, total: 1.15 s
Wall time: 1.2 s

Without any special tweaking, datashader is able to reveal the overall shape of this distribution faithfully: four summed 2D normal distributions of different variances, arranged at the corners of a square, overlapping another very high-variance 2D normal distribution centered in the square. This immediately obvious structure makes a great starting point for exploring the data, and you can then customize each of the various stages involved as described below.
Of course, this is just a static plot, and you can’t see what the axes are, so we can instead embed this data into an interactive plot if we prefer:
import holoviews as hv
from holoviews.operation.datashader import datashade
hv.extension("bokeh")
datashade(hv.Points(df)).opts(width=700, height=700)


Here, if you are running a live Python process, you can enable the “wheel zoom” tool on the right, zoom in anywhere in the distribution, and datashader will render a new image that shows the full distribution at that new location. If you are viewing this on a static web site, zooming will simply make the existing set of pixels larger, because this dynamic updating requires Python.
Now that you can see the overall result, we’ll unpack each of the steps in the Datashader pipeline and show how this image is constructed from the data.
Projection#
Datashader is designed to render datasets projected on to a 2D rectangular grid, eventually generating an image where each pixel corresponds to one cell in that grid. The Projection stage is primarily conceptual, as it consists of you deciding what you want to plot and how you want to plot it:
Variables: Select which variable you want to have on the x axis, and which one for the y axis. If those variables are not already columns in your dataframe (e.g. if you want to do a coordinate transformation), you’ll need to create suitable columns mapping directly to x and y for use in the next step. For this example, the “x” and “y” columns are conveniently named
xandyalready, but any column name can be used for these axes.Ranges: Decide what ranges of those values you want to map onto the scene. If you omit the ranges, datashader will calculate the ranges from the data values, but you will often wish to supply explicit ranges for three reasons:
Calculating the ranges requires a complete pass over the data, which takes nearly as much time as actually aggregating the data, so your plots will be about twice as fast if you specify the ranges.
Real-world datasets often have some outliers with invalid values, which can make it difficult to see the real data, so after your first plot you will often want to specify only the range that appears to have valid data.
Over the valid range of data, you will often be mainly interested in a specific region, allowing you to zoom in to that area (though with an interactive plot you can always do that as needed).
Axis types: Decide whether you want
'linear'or'log'axes.Resolution: Decide what size of aggregate array you are going to want.
Here’s an example of specifying a Canvas (a.k.a. “Scene”) object for a 200x200-pixel image covering the range +/-8.0 on both axes:
canvas = ds.Canvas(plot_width=300, plot_height=300,
x_range=(-8,8), y_range=(-8,8),
x_axis_type='linear', y_axis_type='linear')
At this stage, no computation has actually been done – the canvas object is a purely declarative, recording your preferences to be applied in the next stage.
Aggregation#
Once a Canvas object has been specified, it can then be used to guide aggregating the data into a fixed-sized grid. Data is assumed to consist of a series of items, each of which has some visible representation (its rendering as a “glyph”) that is combined with the representation of other items to produce an aggregate representation of the whole set of items in the rectangular grid. The available glyph types for representing a data item are currently:
Canvas.points: each data item is a coordinate location (an x,y pair), mapping into the single closest grid cell to that datapoint’s location.
Canvas.line: each data item is a coordinate location, mapping into every grid cell falling between this point’s location and the next in a straight line segment.
Canvas.area: each data item is a coordinate location, rendered as a shape filling the axis-aligned area between this point, the next point, and a baseline (e.g. zero, filling the area between a line and a base).
Canvas.trimesh: each data item is a triple of coordinate locations specifying a triangle, filling in the region bounded by that triangle.
Canvas.polygons: each data item is a sequence of coordinate locations specifying a polygon, filling in the region bounded by that polygon (minus holes if specified separately).
Canvas.raster: the collection of data items is an array specifying regularly spaced axis-aligned rectangles forming a regular grid; each cell in this array is rendered as a filled rectangle.
Canvas.quadmesh: the collection of data items is an array specifying irregularly spaced quadrilaterals forming a grid that is regular in the input space but can have arbitrary rectilinear or curvilinear shapes in the aggregate grid; each cell in this array is rendered as a filled quadrilateral.
These types are each covered in detail in the User Guide. Many other plots like time series and network graphs can be constructed out of these basic primitives. Datashader can also be extended to add additional types here and in each section below; see Extending Datashader for more details.
2D Reductions#
Once you have determined your mapping, you’ll next need to choose a reduction operator to use when aggregating multiple datapoints into a given pixel. For points, each datapoint is mapped into a single pixel, while the other glyphs have spatial extent and can thus map into multiple pixels, each of which operates the same way. All glyphs act like points if the entire glyph is contained within that pixel. Here we will talk only about “datapoints” for simplicity, which for an area-based glyph should be interpreted as “the part of that glyph that falls into this pixel”.
All of the currently supported reduction operators are incremental, which means that we can efficiently process datasets in a single pass. Given an aggregate bin to update (typically corresponding to one eventual pixel) and a new datapoint, the reduction operator updates the state of the bin in some way. (Actually, datapoints are normally processed in batches for efficiency, but it’s simplest to think about the operator as being applied per data point, and the mathematical result should be the same.) A large number of useful reduction operators are supplied in ds.reductions, including:
count(column=None):
increment an integer count each time a datapoint maps to this bin. The resulting aggregate array will be an unsigned integer type, allowing counts to be distinguished from the other types that are normally floating point.
any(column=None):
the bin is set to 1 if any datapoint maps to it, and 0 otherwise.
sum(column):
add the value of the given column for this datapoint to a running total for this bin.
summary(name1=op1,name2=op2,...):
allows multiple reduction operators to be computed in a single pass over the data; just provide a name for each resulting aggregate and the corresponding reduction operator to use when creating that aggregate. If multiple aggregates are needed for the same dataset and the same Canvas, using summary will generally be much more efficient than making multiple separate passes over the dataset.
The API documentation contains the complete list of reduction operators provided, including mean, min, max, var (variance), std (standard deviation). The reductions are also imported into the datashader namespace for convenience, so that they can be accessed like ds.mean() here.
For the operators above, those accepting a column argument will only do the operation if the value of that column for this datapoint is not NaN. E.g. count with a column specified will count the datapoints having non-NaN values for that column.
Once you have selected your reduction operator, you can compute the aggregation for each pixel-sized aggregate bin:
canvas.points(df, 'x', 'y', agg=ds.count())
<xarray.DataArray (y: 300, x: 300)> Size: 360kB
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], shape=(300, 300), dtype=uint32)
Coordinates:
* y (y) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* x (x) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
Attributes:
x_range: (-8, 8)
y_range: (-8, 8)The result of will be an xarray DataArray data structure containing the bin values (typically one value per bin, but more for multiple category or multiple-aggregate operators) along with axis range and type information.
We can visualize this array in many different ways by customizing the pipeline stages described in the following sections, but for now we’ll simply render images using the default parameters to show the effects of a few different aggregate operators:
tf.Images(tf.shade( canvas.points(df,'x','y', ds.count()), name="count()"),
tf.shade( canvas.points(df,'x','y', ds.any()), name="any()"),
tf.shade( canvas.points(df,'x','y', ds.mean('y')), name="mean('y')"),
tf.shade(50-canvas.points(df,'x','y', ds.mean('val')), name="50- mean('val')"))
count() | any() | mean('y') | 50- mean('val') |
Here count() renders each possible count in a different color, to show the statistical distribution by count, while any() turns on a pixel if any point lands in that bin, and mean('y') averages the y column for every datapoint that falls in that bin. Of course, since every datapoint falling into a bin happens to have the same y value, the mean reduction with y simply scales each pixel by its y location.
For the last image above, we specified that the val column should be used for the mean reduction, which in this case results in each category being assigned a different shade of blue, because in our dataset all items in the same category happen to have the same val. Here we also manipulated the result of the aggregation before displaying it by subtracting it from 50, a Transformation as described in more detail below.
3D Reductions#
The above examples are 2D reductions that generate a single x × y aggregate array when given a particular reduction operator. You can instead supply a by reduction operator to do 3D reductions, resulting in a stack of aggregate arrays, x × y × c, where c is some other column:
by(column, reduction):
create a 3D stack of aggregates, with each datapoint contributing to one of the aggregate arrays according to the value of the indicated categorical column or categorizer object and using the indicated 2D reduction operator to create each 2D array in the 3D stack.
The resulting 3D stack can later be selected or collapsed into a 2D array for visualization, or the third dimension can be used for colormappping to generate an x × y × color image.
For instance, to aggregate counts by our categorical cat dimension:
aggc = canvas.points(df, 'x', 'y', ds.by('cat', ds.count()))
aggc
<xarray.DataArray (y: 300, x: 300, cat: 5)> Size: 2MB
array([[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
...
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]], shape=(300, 300, 5), dtype=uint32)
Coordinates:
* y (y) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* x (x) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* cat (cat) <U2 40B 'd1' 'd2' 'd3' 'd4' 'd5'
Attributes:
x_range: (-8, 8)
y_range: (-8, 8)Here the count() aggregate has been collected into not just one 2D aggregate array, but a whole stack of aggregate arrays, one per cat value, making the aggregate be three dimensional x × y × cat rather than just two x × y.
With this 3D aggregate of counts per category, you can then select a specific category or subset of them for further processing, where .sum(dim='cat') will collapse across such a subset to give a single aggregate array:
agg_d3_d5=aggc.sel(cat=['d3', 'd5']).sum(dim='cat').astype('uint32')
tf.Images(tf.shade(aggc.sel(cat='d3'), name="Category d3"),
tf.shade(agg_d3_d5, name="Categories d3 and d5"))
Category d3 | Categories d3 and d5 |
by also works with numerical (non-categorical) axes when given a “categorizer” object for the column, allowing binning over three numerical dimensions:
categorizer = ds.category_binning('val', lower=10, upper=50, nbins=4, include_under=False, include_over=False)
agg3D = canvas.points(df, 'x', 'y', ds.by(categorizer, ds.count()))
agg3D
<xarray.DataArray (y: 300, x: 300, val: 5)> Size: 2MB
array([[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
...
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]],
[[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
...,
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]], shape=(300, 300, 5), dtype=uint32)
Coordinates:
* y (y) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* x (x) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* val (val) int64 40B 0 1 2 3 4
Attributes:
x_range: (-8, 8)
y_range: (-8, 8)Here agg3D does a 3D histogram over the x × y × val space, counting how many data points fall in each bin of this three-dimensional cube. We requested that the val range (10,50) be divided into 4 bins, which results in 5 aggregate arrays by val:
0:
valvalues in the range [10,20) (including values below 10, ifinclude_under==True(the default)1:
valvalues in the range [20,30)2:
valvalues in the range [30,40)3:
valvalues in the range [40,50) (including values above 50, ifinclude_over==True(the default)4:
valvalues of NaN or other values not falling into any of the above bins (depending oninclude_underandinclude_over)
category_modulo works similarly, but wrapping the given range cyclicly, for cyclic quantities like the day of the week:
modulo_categorizer = ds.category_modulo('val', modulo=7, offset=0)
agg3D_modulo = canvas.points(df, 'x', 'y', ds.by(modulo_categorizer, ds.mean('x')))
agg3D_modulo
<xarray.DataArray (y: 300, x: 300, val: 7)> Size: 5MB
array([[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
...
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]]], shape=(300, 300, 7))
Coordinates:
* y (y) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* x (x) float64 2kB -7.973 -7.92 -7.867 -7.813 ... 7.867 7.92 7.973
* val (val) int64 56B 0 1 2 3 4 5 6
Attributes:
x_range: (-8, 8)
y_range: (-8, 8)Here the resulting aggregate arrays bin by (val-0)%7:
0:
valvalues 0, 7, 14, etc.1:
valvalues 1, 8, 15, etc.2:
valvalues 2, 9, 16, etc.3:
valvalues 3, 10, 17, etc.4:
valvalues 4, 11, 18, etc.5:
valvalues 5, 12, 19, etc.6:
valvalues 6, 13, 20, etc.
Other custom categorizers can also be defined as new Python classes; see category_codes in reductions.py.
As for aggc, the agg3D and agg3D_modulo arrays can then be selected or collapsed to get a 2D aggregate array for display, or each val can be mapped to a different color for display in the colormapping stage.
Transformation#
Now that the data has been projected and aggregated into a 2D or 3D gridded data structure, it can be processed in any way you like, before converting it to an image as will be described in the following section. At this stage, the data is still stored as bin data, not pixels, which makes a very wide variety of operations and transformations simple to express.
For instance, instead of plotting all the data, we can easily plot only those bins in the 99th percentile by count (left), or apply any NumPy ufunc to the bin values (whether or not it makes any sense!):
agg = canvas.points(df, 'x', 'y')
tf.Images(tf.shade(agg.where(agg>=np.percentile(agg,99)), name="99th Percentile"),
tf.shade(np.power(agg,2), name="Numpy square ufunc"),
tf.shade(np.sin(agg), name="Numpy sin ufunc"))
99th Percentile | Numpy square ufunc | Numpy sin ufunc |
You can also combine multiple aggregates however you like, as long as they were all constructed using the same Canvas object (which ensures that their aggregate arrays are the same size) and cover the same axis ranges. Here, let’s use our 3D categorical aggregate to compute using the category information:
sel1 = agg_d3_d5.where(aggc.sel(cat='d3') == aggc.sel(cat='d5'), other=-1).astype('uint32')
sel2 = agg.where(aggc.sel(cat='d3') == aggc.sel(cat='d5'), other=-1).astype('uint32')
tf.Images(tf.shade(sel1, name='d3+d5 where d3==d5'),
tf.shade(sel2, name='d1+d2+d3+d4+d5 where d3==d5'))
d3+d5 where d3==d5 | d1+d2+d3+d4+d5 where d3==d5 |
This operation specifies uint32 because at least current versions of xarray’s where method convert to floating point, and keeping the type unsigned is important for shade to know that zero is a missing-data value here, to be rendered with a transparent background.
The above two results are using the same mask (only those bins where the counts for ‘d3’ and ‘d5’ are equal), but applied to different aggregates (either just the d3 and d5 categories, or the entire set of counts).
The xarray documentation describes all the various transformations you can apply from within xarray, and of course you can always extract the data values and operate on them outside of xarray for any transformation not directly supported by xarray, then construct a suitable xarray object for use in the following stage. Once the data is in the aggregate array, you generally don’t have to worry much about optimization, because it’s a fixed-sized grid regardless of your data size, and so it is very straightforward to apply arbitrary transformations to the aggregates.
Spreading#
Several predefined transformation functions are provided in ds.transfer_functions. The most important of these is tf.spread, which implements pixel “spreading”. For background, Datashader doesn’t currently allow data points to have any spatial extent as they would in a typical plotting program. Instead, points are treated as their mathematical ideal and thus contribute to at most one pixel in the image, which is appropriate for a large dataset with many data points per pixel. What about when you have zoomed into a small or sparse region of the dataset, with few data points? Isolated single pixels like that can be very difficult to see, so Datashader supports “spreading” to transform the aggregate by replacing each pixel with a shape, such as a circle (default) or square:
img = tf.shade(agg, name="Original image")
tf.Images(img,
tf.shade(tf.spread(agg, name="spread 1px")),
tf.shade(tf.spread(agg, px=3, name="spread 2px")),
tf.shade(tf.spread(agg, px=5, shape='square', name="spread square")))
| Original image | spread 1px | spread 2px | spread square |
As you can see, spreading is very effective for isolated datapoints, which is what it’s normally used for, but it has overplotting-like effects for closely spaced points, so it should be avoided when the datapoints are dense. For interactive usage, where spreading is desirable when zoomed in closely but undesirable when zoomed out to see more data, Datashader provides the dynspread function that will dynamically calculate the px to use in spread by counting the fraction of non-masked bins that have non-masked neighbors; see the
dynspread docs for more details.
Spreading can be used with a custom mask, as long as it is square and an odd width and height (so that it will be centered over the original pixel):
box = np.array([[1, 1, 1, 1, 1],
[1, 0, 0, 0, 1],
[1, 0, 0, 0, 1],
[1, 0, 0, 0, 1],
[1, 1, 1, 1, 1]])
cross = np.array([[1, 0, 0, 0, 1],
[0, 1, 0, 1, 0],
[0, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 0, 0, 1]])
tf.Images(tf.shade(tf.spread(agg, mask=box), name="Custom box mask"),
tf.shade(tf.spread(agg, mask=cross), name="Custom cross mask"))
Custom box mask | Custom cross mask |
Colormapping#
As you can see above, the usual way to visualize an aggregate array is to map from each array bin into a color for a corresponding pixel in an image. The above examples use the tf.shade() method, which maps a scalar aggregate bin value into an RGB (color) triple and an alpha (opacity) value. By default, the colors are chosen from the colormap [‘lightblue’,’darkblue’] (i.e., #ADD8E6 to #00008B), with intermediate colors chosen as a linear interpolation independently for the red, green, and blue color channels (e.g. AD to 00 for the red channel, in this case).
Empty values (pixels without any data points in them) are treated specially, using the opacity (alpha) of the image to let the page background show through. For a floating-point aggregate, empty values have a value of NaN, while for unsigned integer aggregates a value of 0 is treated as empty (e.g. zero counts of data in that pixel).
To control the colors used, you can supply any Bokeh palette, Matplotlib colormap, or list of colors (using the color names from ds.colors, integer triples, or hexadecimal strings):
from bokeh.palettes import RdBu9
tf.Images(tf.shade(agg,cmap=["darkred", "yellow"], name="darkred, yellow"),
tf.shade(agg,cmap=[(230,230,0), "orangered", "#300030"], name="yellow, orange red, dark purple"),
tf.shade(agg,cmap=list(RdBu9), name="Bokeh RdBu9"),
tf.shade(agg,cmap="black", name="Black"))
darkred, yellow | yellow, orange red, dark purple | Bokeh RdBu9 | Black |
As a special case (“Black”, above), if you supply only a single color, the color will be kept constant at the given value but the alpha (opacity) channel will vary with the data, starting at min_alpha for the lowest data value and going to full opacity.
Colormapping 3D categorical data#
A categorical aggregate like aggc above is like a 3D stack of separate aggregate arrays, one array per possible category value. Of course, you can use tf.shade on each of those separate arrays individually by first selecting a single category using something like aggc.sel(cat='d3'). You can also collapse all categories into a single aggregate using something like aggc.sum(dim='cat'), and then shade that collapsed array as usual.
But if you want to look at all categories simultaneously, you can create a single image using a different color for each category. Just pass the 3D categorical aggregate stack directly to tf.shade, which will assign a color to each category and then calculate the transparency and color of each pixel according to each category’s contribution to that pixel:
color_key = dict(d1='blue', d2='green', d3='red', d4='orange', d5='purple')
tf.Images(tf.shade(aggc, name="Default color key"),
tf.shade(aggc, color_key=color_key, name="Custom color key"))
Default color key | Custom color key |
Here the different colors mix not just visually due to blurring, but are actually mixed mathematically per pixel, such that pixels that include data from multiple categories will take intermediate color values. The total (summed) data values across all categories are used to calculate the alpha channel, with the previously computed color being revealed to a greater or lesser extent depending on the value of the aggregate for that bin. Thus you can still see which pixels have the highest counts (as they have a higher opacity and thus have brighter colors here), while the specific colors show you which category(ies) are most common in each pixel. See Colormapping with negative values below for more details on how these colors and transparencies are calculated.
The default color key for categorical data provides distinguishable colors for a couple of dozen categories, but you can provide an explicit color_key as a list or dictionary if you prefer. Choosing colors for different categories is more of an art than a science, because the colors not only need to be distinguishable, their combinations also need to be distinguishable if those categories ever overlap in nearby pixels, or else the results will be ambiguous. In practice, only a few categories can be reliably distinguished in this way, but zooming in can be used to help disambiguate overlapping colors, as long as the basic set of colors is itself distinguishable.
Colormapping 2D categorical data#
For a 3D categorical aggregate, Datashader has computed an entire distribution of values in each pixel, and then shading mixes all the corresponding colors to compute a single color for that pixel. What if you are using a 2D aggregate with a reduction function like ds.min that ensures that each pixel has only a single category assigned to it? In that case you can shade it just as for the 3D case, but directly mapping from a pixel’s numerical value to the corresponding categorical color:
aggc_2d = canvas.points(df, 'x', 'y', ds.min('val'))
custom_cats_colorkey = {10: 'blue', 20: 'green', 30: 'red'}
all_cats_colorkey = {10: 'blue', 20: 'green', 30: 'red', 40: 'orange', 50: 'purple'}
tf.Images(tf.shade(aggc_2d, color_key=custom_cats_colorkey, name="Custom categories - 2D"),
tf.shade(aggc_2d, color_key=all_cats_colorkey, name="All categories - 2D"))
Custom categories - 2D | All categories - 2D |
Here you can compare the “All categories - 2D” plot to the “Custom color key” plot in the previous section to see that this 2D-aggregate plot has only a single, full-strength color per pixel, with no color mixing and no scaling by opacity; each pixel simply reports the color from the key that corresponds to the minimum value encountered for that pixel in the data.
Transforming data values for colormapping#
In each of the above examples, you may have noticed that we were never required to specify any parameters about the data values; the plots just appear like magic. That magic is implemented in tf.shade. What tf.shade does for a 2D aggregate (non-categorical) is:
Mask out all bins with a
NaNvalue (for floating-point arrays) or a zero value (for the unsigned integer arrays that are returned fromcount); these bins will not have any effect on subsequent computations.Transform the bin values using a specified scalar function
how. Calculates the value of that function for the difference between each bin value and the minimum non-masked bin value. E.g. forhow="linear", simply returns the difference unchanged. Otherhowfunctions are discussed below.Map the resulting transformed data array into the provided colormap. First finds the value span (l,h) for the resulting transformed data array – what are the lowest and highest non-masked values? – and then typically maps the range (l,h) into the full range of the colormap provided. If a colormap is used, masked values are given a fully transparent alpha value, and non-masked ones are given a fully opaque alpha value. If a single color is used, the alpha value starts at
min_alphaand increases proportionally to the mapped data value up to the fullalphavalue.
The result is thus auto-ranged to show whatever data values are found in the aggregate bins, with the span argument (described below) allowing you to override the range explicitly if you need to.
As described in Plotting Pitfalls, auto-ranging is only part of what is required to reveal the structure of the dataset; it’s also crucial to automatically and potentially nonlinearly map from the aggregate values (e.g. bin counts) into the colormap. If we used a linear mapping, we’d see very little of the structure of the data:
tf.shade(agg,how='linear')

In the linear version, you can see that the bins that have zero count show the background color, since they have been masked out using the alpha channel of the image, and that the rest of the pixels have been mapped to colors near the bottom of the colormap. If you peer closely at it, you may even be able to see that one pixel (from the smallest Gaussian) has been mapped to the highest color in the colormap (here dark blue). But no other structure is visible, because the highest-count bin is so much higher than all of the other bins:
top15=agg.values.flat[np.argpartition(agg.values.flat, -15)[-15:]]
print(sorted(top15))
print(sorted(np.round(top15*255.0/agg.values.max()).astype(int)))
[np.uint32(342), np.uint32(345), np.uint32(345), np.uint32(351), np.uint32(355), np.uint32(357), np.uint32(363), np.uint32(392), np.uint32(399), np.uint32(405), np.uint32(1075), np.uint32(1148), np.uint32(1169), np.uint32(1172), np.uint32(3918)]
[np.int64(22), np.int64(22), np.int64(22), np.int64(23), np.int64(23), np.int64(23), np.int64(24), np.int64(26), np.int64(26), np.int64(26), np.int64(70), np.int64(75), np.int64(76), np.int64(76), np.int64(255)]
I.e., if using a colormap with 255 colors, the largest bin (agg.values.max()) is mapped to the highest color, but with a linear scale all of the other bins map to only the first 24 colors, leaving all intermediate colors unused. If we want to see any structure for these intermediate ranges, we need to transform these numerical values somehow before displaying them. For instance, if we take the logarithm of these large values, they will be mapped into a more tractable range:
print(np.log1p(sorted(top15)))
[5.83773045 5.84643878 5.84643878 5.86363118 5.87493073 5.88053299
5.89715387 5.97380961 5.99146455 6.00635316 6.98100574 7.04664728
7.06475903 7.06731985 8.2735918 ]
So we can plot the logarithms of the values (how='log', below), which is an arbitrary transform but is appropriate for many types of data. A more general approach that doesn’t make any assumptions about the data distribution is to use histogram equalization, where Datashader makes a histogram of the numeric values, then assigns a pixel color to each equal-sized histogram bin to ensure even usage of every displayable color (how='eq_hist'; see plotting pitfalls). We can even supply any arbitrary transformation to the colormapper as a callable, such as a twenty-third root:
tf.Images(tf.shade(agg,how='log', name="log"),
tf.shade(agg,how='eq_hist', name="eq_hist"),
tf.shade(agg,how=lambda d, m: np.where(m, np.nan, d)**(1/23.), name="23rd root"))
log | eq_hist | 23rd root |
Because Datashader is designed to reveal the properties of your dataset without making any assumptions about its range or form, the default transformation is eq_hist; you can select any other how option for tf.shade if you know it is appropriate for your particular dataset.
Note that histogram equalization dynamically scales the input aggregate values into the entire colormap range, which is appropriate when you have a large dataset, using all available colors to convey properties of the data being displayed. However, in small-data cases where you are looking at widely separated, rarely overlapping points, most datapoints would end up being colored with the lowest colormap value (here a barely visible light blue color), with the highest (and thus most visible) colormap value reserved for the occasional overlapping points:
zoom_agg = ds.Canvas(plot_width=300, plot_height=300, x_range=(1.92,1.95), y_range=(1.92,1.95)).points(df, 'x', 'y')
zoom = tf.spread(zoom_agg, px=3)
tf.Images(tf.shade(zoom, how='eq_hist', name="eq_hist rescale_discrete_levels=False", rescale_discrete_levels=False),
tf.shade(zoom, how='eq_hist', name="eq_hist rescale_discrete_levels=True", rescale_discrete_levels=True))
eq_hist rescale_discrete_levels=False | eq_hist rescale_discrete_levels=True |
To support interactive usage where you want the full colormap range available when plotting many points, but for individual points to be more visible when there are only a few discrete levels (two, in the plots above), as of Datashader 0.14 you can specify rescale_discrete_levels=True to use only the upper end of the colormap range, letting values be distinguished while making all points similarly visible (as in the eq_hist rescale_discrete_levels=True plot above).
Of course, the how options like logarithmic scaling and histogram equalization can be considered part of the Transformation stage, but in practice these well-defined transformations are applied during colormapping (“shading”) so that the raw aggregate values can be kept in their untransformed state suitable for direct numerical lookup during the subsequent Embedding stage. That way, interactive hovering and colorbars can report the accurate untransformed values. See the shade docs for more details on the how functions.
For categorical aggregates, the shade function works similarly to providing a single color to a non-categorical aggregate, with the alpha (opacity) calculated from the total value across all categories (and the color calculated as a weighted mixture of the colors for each category).
Controlling ranges for colormapping#
By default, shade will autorange on the aggregate array, mapping the lowest and highest values of the aggregate array into the lowest and highest values of the colormap (or the available alpha values, for single colors). You can instead focus on a specific span of the aggregate data values, mapping that span into the available colors or the available alpha values:
tf.Images(tf.shade(agg,cmap=["grey", "blue"], name="gb 0 20", span=[0,20], how="linear"),
tf.shade(agg,cmap=["grey", "blue"], name="gb 50 200", span=[50,200], how="linear"),
tf.shade(agg,cmap="green", name="Green 10 20", span=[10,20], how="linear"))
gb 0 20 | gb 50 200 | Green 10 20 |
On the left, all counts above 20 are mapped to the highest value in the colormap (blue in this case), losing the ability to distinguish between values above 20 but providing the maximum color precision for the specific range 0 to 20. In the middle, all values 0 to 50 map to the first color in the colormap (grey in this case), and the colors are then linearly interpolated up to 200, with all values 200 and above mapping to the highest value in the colormap (blue in this case). With the single color mapping to alpha on the right, counts up to 10 are all mapped to min_alpha, counts 20 and above are all mapped to the specified alpha (255 in this case), and alpha is scaled linearly in between.
For plots that scale with alpha (i.e., categorical or single-color non-categorical plots), you can control the range of alpha values generated by setting min_alpha (lower bound) and alpha (upper bound), on a scale 0 to 255):
tf.Images(tf.shade(agg,cmap="green", name="Green"),
tf.shade(agg,cmap="green", name="No min_alpha", min_alpha=0),
tf.shade(agg,cmap="green", name="Small alpha range", min_alpha=50, alpha=80))
Green | No min_alpha | Small alpha range |
Here you can see that the faintest pixels are more visible with the default min_alpha (normally 40, left) than if you explicitly set the min_alpha=0 (middle), which is why the min_alpha default is non-zero; otherwise low values would be indistinguishable from the background (see Plotting Pitfalls).
You can combine span and alpha ranges to specifically control the data value range that maps to an opacity range, for single-color and categorical plotting:
tf.Images(tf.shade(agg,cmap="green", name="g 0,20", span=[ 0,20], how="linear"),
tf.shade(agg,cmap="green", name="g 10,20", span=[10,20], how="linear"),
tf.shade(agg,cmap="green", name="g 10,20 0", span=[10,20], how="linear", min_alpha=0))
g 0,20 | g 10,20 | g 10,20 0 |
tf.Images(tf.shade(aggc, name="eq_hist"),
tf.shade(aggc, name="linear", how='linear'),
tf.shade(aggc, name="span 0,10", how='linear', span=(0,10)),
tf.shade(aggc, name="span 0,10", how='linear', span=(0,20), min_alpha=0))
| eq_hist | linear | span 0,10 | span 0,10 |
The categorical examples above focus on counts, but ds.by works on other aggregate types as well, colorizing by category but aggregating by sum, mean, etc. (but see the following section for details on how to interpret such colors):
agg_c = canvas.points(df,'x','y', ds.by('cat', ds.count()))
agg_s = canvas.points(df,'x','y', ds.by("cat", ds.sum("val")))
agg_m = canvas.points(df,'x','y', ds.by("cat", ds.mean("val")))
tf.Images(tf.shade(agg_c), tf.shade(agg_s), tf.shade(agg_m))
|  |  |
Colormapping with negative values#
The above examples all use positive data values to avoid confusion when there is no colorbar or other explicit indication of a z (color) axis range. Negative values are also supported, in which case for a non-categorical plot you should normally use a diverging colormap
from colorcet import coolwarm, CET_D8
dfn = df.copy()
dfn["val"] = dfn["val"].replace({20: -20, 30: 0, 40: -40})
aggn = ds.Canvas().points(dfn,'x','y', agg=ds.mean("val"))
tf.Images(tf.shade(aggn, name="Sequential", cmap=["lightblue","blue"], how="linear"),
tf.shade(aggn, name="DivergingW", cmap=coolwarm[::-1], span=(-50,50), how="linear"),
tf.shade(aggn, name="DivergingB", cmap=CET_D8[::-1], span=(-50,50), how="linear"))
Sequential | DivergingW | DivergingB |
In both of the above plots, values with no data are transparent as usual, showing white. With a sequential lightblue to blue colormap, increasing val numeric values are mapped to the colormap in order, with the smallest values (-40; large blob in the top left) getting the lowest color value (lightblue), less negative values (-20, blob in the bottom right) getting an intermediate color, and the largest average values (50, large distribution in the background) getting the highest color. Looking at such a plot, viewers have no easy way to determine which values are negative. Using a diverging colormap (right two plots) and forcing the span to be symmetric around zero ensures that negative values are plotted in one color range (reds) and positive are plotted in a clearly different range (blues). Note that when using a diverging colormap with transparent values, you should carefully consider what you want to happen around the zero point; here values with nearly zero average (blob in bottom left) disappear when using a white-centered diverging map (“coolwarm”), while they show up but in a neutral color when using a diverging map with a contrasting central color (“CET_D8”).
For categorical plots of values that can be negative, the results are often quite difficult to interpret, for the same reason as for the Sequential case above:
agg_c = canvas.points(dfn,'x','y', ds.by('cat', ds.count()))
agg_s = canvas.points(dfn,'x','y', ds.by("cat", ds.sum("val")))
agg_m = canvas.points(dfn,'x','y', ds.by("cat", ds.mean("val")))
tf.Images(tf.shade(agg_c, name="count"),
tf.shade(agg_s, name="sum"),
tf.shade(agg_s, name="sum baseline=0", color_baseline=0))
| count | sum | sum baseline=0 |
Here a count aggregate ignores the negative values and thus works the same as when values were positive, but sum and other aggregates like mean take the negative values into account. By default, a pixel with the lowest value (whether negative or positive) maps to min_alpha, and the highest maps to alpha. The color is determined by how different each category’s value is from the minimum value across all categories; categories with high values relative to the minimum contribute more to the color. There is not currently any way to tell which data values are positive or negative, as you can using a diverging colormap in the non-categorical case.
Instead of using the default of the data minimum, you can pass a specific color_baseline, which is appropriate if your data has a well-defined reference value such as zero. Here, when we pass color_baseline=0 the negative values are essentially ignored for color calculations, which can be seen on the green blob, where any orange data point is fully orange despite the presence of green-category datapoints; the middle plot sum shows a more appropriate color mixture in that case.
RGB transformations#
Just as for the aggregate array, the RGB image can also be transformed, e.g. with spreading:
img = tf.shade(aggc, name="Original image")
tf.Images(img,
tf.shade(tf.spread(aggc, px=3, name="Aggregate spreading")),
tf.spread(img, px=3, name="RGB spreading"))
| Original image | Aggregate spreading | RGB spreading |
In practice, aggregate spreading is a better choice, since RGB’s fixed 0,1 scale will cause visible artifacts in dense regions like the purple area above.
Other image operations provided are more useful, such as setting the background color or combining images:
sum_d2_d3 = aggc.sel(cat=['d2', 'd3']).sum(dim='cat').astype('uint32')
tf.Images(tf.set_background(img,"black", name="Black bg"),
tf.stack(img,tf.shade(sum_d2_d3), name="Sum d2 and d3 colors"),
tf.stack(img,tf.shade(sum_d2_d3), name="d2+d3 saturated", how='saturate'))
Black bg | Sum d2 and d3 colors | d2+d3 saturated |
See the API docs for more details. Image composition operators to provide for the how argument of tf.stack (e.g. over (default), source, add, and saturate) are listed in composite.py and illustrated here.
Embedding#
The steps outlined above represent a complete pipeline from data to images, which is one way to use Datashader. However, in practice one will usually want to add one last additional step, which is to embed these images into a plotting program to be able to get axes, legends, interactive zooming and panning, etc. The next notebook shows how to do such embedding.